목차
들어가며
- 어떤 프로젝트인가
- Day 1 - 데이터 큐레이션
- Day 2 - 데이터 전처리 (LLM으로 재전처리)
- 마무리
들어가며
지난 3개의 글에서는 RAG를 다뤘다. 모델은 그대로 두고, 외부 지식을 검색해서 물려주는 방식이었다.
Week 6~7은 결이 다르다. 이번엔 모델 자체를 우리 문제에 맞게 똑똑하게 만드는 파인튜닝(fine-tuning)을 말로만 듣다 드디어 해본다.
LLM을 똑똑하게 쓰는 방법은 크게 두 갈랜데,
- 추론 시점(inference-time)에 손대는 법: 멀티샷 프롬프팅, 툴/펑션 콜링, RAG 등 -> 모델은 그대로 두고 입력을 잘 차려주는 쪽
- 학습(training)으로 모델을 바꾸는 법: 파인튜닝 -> 모델의 파라미터(가중치) 자체를 우리 데이터에 맞게 다시 조정
RAG를 다뤘던 Week 5(지난 3개의 글)까지가 전자였다면, Week 6~7은 후자로 넘어간다.
Week 6~7 은 캡스톤 프로젝트 형식으로 진행하는데 상품의 설명을 기반으로 가격을 맞추는 "THE PRICE IS RIGHT"라는 프로젝트를 진행한다.
- Week 6에서는 초반부에 관련 데이터를 모으고 전처리 한뒤, 여러 모델로 가격을 맞춰본 뒤 프론티어 모델 (GPT)를 파인튜닝
- Week 7은 오픈소스 모델(라마)를 파인튜닝해서 성능을 보는 작업을 진행
이 글에서는 Week 6에서의 앞 이틀, 데이터를 만들고 전처리하는 과정(Day 1-2)을 다룬다.
모델을 돌리고 파인튜닝하는 Day 3-5는 다음 글에서 이어 간다.
1. 어떤 프로젝트인가
이번 프로젝트의 목표는 상품 설명(텍스트)을 주면, 그 상품의 가격(숫자)을 예측하는 모델을 만든다.
입력은 "스테인리스 텀블러 600ml, 보온 6시간, 브랜드 X" 같은 상품 설명이고, 출력은 "$24.90" 같은 값이다.
여기서 자연스러운 의문이 든다. 가격 예측은 전통적인 회귀 모델(선형회귀 같은)이 원래 잘하는 영역인데, 왜 굳이 LLM을 쓰나?
강의에서 짚어 준 이유는 세 가지였다.
- 평가가 명확하다(clear and tangible eval): 정답 가격이 있으니 "예측가와 실제가의 차이"처럼 숫자로 딱 떨어지게 성능을 잴 수 있다. "대화 잘했네" 같은 주관 평가가 아니다.
- 언어 뉘앙스/세부 맥락을 LLM은 잘 파악한다: 상품 설명은 정돈된 표가 아니라 텍스트 뭉치다. 같은 "60인치 TV"라도 그냥 TV인지, 스마트 TV인지, 럭셔리 포지셔닝인지에 따라 가격이 갈린다. LLM은 이런 뉘앙스(속성 추출 + 의미 해석)를 잘한다 -> 가격 예측 성능이 잘 나올 수 있음
- 프론티어 모델이 원래 이걸 잘한다: 최신 모델은 무수히 많은 인터넷 학습 데이터에서 얻은 감 덕에 "대충 말이 되는" 가격을 꽤 잘 부른다.
6주 차 전체 로드맵은 이렇게 흘러간다.
- Day 1: 데이터 큐레이션 (데이터 수집·정제)
- Day 2: 데이터 전처리 (표준 포맷으로 재작성)
- Day 3: 평가·베이스라인·전통 ML
- Day 4: 딥러닝과 LLM
- Day 5: 프론티어 모델 파인튜닝
느낀 점
- 평가가 명확할 수 있는 영역으로 프로젝트를 진행한 것이 인상적(어떤 게 더 성능이 좋나를 객관화할 수 있는 영역)
- RAG와 파인튜닝을 "추론 시점에 손대기 vs 학습으로 모델을 바꾸기"로 가르는 프레임이 깔끔했다. 당장은 서비스를 만드는 과정에서 파인튜닝까지 고려해야 할 상황이 많지는 않겠지만, 기획자 입장에서 지금 상황이 파인튜닝까지 고려해야 할 상황일까? 를 고민하는 데 있어 하나의 기준점을 알려준 기분이었다.
- 단순 회귀, 전통 ML이 잘 맞을 거 같은 영역으로 보이지만 LLM 만의 장점이 있을 수 있다는 걸 알려준 점이 인상적이었다. (언어의 뉘앙스 캐치 등)
2. Day 1 - 데이터 큐레이션
2-1) 좋은 데이터는 어디서 오나
본격적인 코드에 들어가기 전에, 강의에서 데이터 소스 후보를 정리해 줬다.
- 내가 이미 가지고 있는 데이터
- Kaggle
- 허깅페이스 데이터셋
- 합성 데이터(synthetic data)
- scale.com 같은 데이터 전문 업체
그리고 데이터는 늘 세 가지로 나눈다.
- 학습 데이터(train): 모델의 내부 파라미터를 조정하는 데 쓴다.
- 검증 데이터(validation): 학습에 포함되지 않은 데이터. 훈련 중에 반복적으로 들여다보며 "더 나아지고 있나, 나빠지고 있나"를 확인한다.
- 테스트 데이터(test): 마지막에 딱 한 번, 일반화가 잘 되는지(과적합이 되진 않았는지) 최종 판정에 쓴다.
전통 ML에서는 보통 80/10/10으로 나누는 경향이 많다고 설명해줬고, LLM에서는 학습에 훨씬 많은 데이터를 쓴다고 강의에서 말해줬다.
(워낙 다루는 데이터의 양이 크다 보니까, 학습 데이터에서 최대한 손실이 나는 걸 방지하고 싶은 것일까 싶기도 하고)
성능 평가 지표도 두 갈래로 안내해줬다.
- 모델 중심(model-centric): loss, LLM에서는 cross-entropy loss. 모델이 결과를 얼마나 잘못 예측했는지를 본다.
- 비즈니스 중심(business-centric): 실제 가격 차이, MSE(예측 가격과 실제 가격 차이를 제곱한 값) 같은 것. 이번 프로젝트의 진짜 목표 지표다.
=> 실제 모델 쪽 같은 경우는 이런 모델 중심(기술 지표)과 프로젝트 목적에 맞는 비즈니스 지표를 복합적으로 보는 게 중요하다 느꼈다.
2-2) 데이터셋 불러오기
이번에 쓸 데이터는 McAuley-Lab의 Amazon-Reviews-2023이다.
아마존 상품 메타데이터가 카테고리별로 정리돼 있다. 먼저 가전(Appliances) 카테고리부터 열어 본다.
from datasets import load_dataset
dataset = load_dataset(
"McAuley-Lab/Amazon-Reviews-2023",
"raw_meta_Appliances",
split="full",
trust_remote_code=True
)
print(f"Number of Appliances: {len(dataset):,}")
출력:
Number of Appliances: 94,327
데이터 한 건을 까 보면, title(상품명), features(특징 리스트), description, price, 그리고 details(브랜드·무게·모델번호 등이 들어 있는 JSON 문자열) 같은 필드가 보인다.

재미 삼아 가장 비싼 가전을 찾아봤다.
max_price = 0
max_item = None
for datapoint in tqdm(dataset):
try:
price = float(datapoint["price"])
if price > max_price:
max_item, max_price = datapoint, price
except ValueError:
pass
print(f"The most expensive is {max_item['title']} at {max_price:,.2f}")
출력:
The most expensive item is TurboChef BULLET Rapid Cook Electric Microwave Convection Oven and it costs 21,095.62
2만 달러짜리 업소용 오븐이다. 이런 극단값은 뒤에서 가격 범위 필터로 걸러진다.

2-3) Item 클래스로 정제하기
원본 데이터셋을 그대로 쓸 수는 없다.
1) 가격이 적당한 범위인지,
2) 설명이 충분히 긴지 걸러야 한다.
(너무 과도하게 비싸거나, 너무 과도하게 설명이 짧은 건 적당히 데이터를 거르는 게 모델 학습엔 좋음)
이 로직은 pricer/parser.py의 parse()와 pricer/items.py의 Item 클래스에 들어 있다. 핵심 규칙은 이렇다.
- 가격이 숫자가 아니면 None 반환
- 가격이 $0.50 - $999.49 범위인 것만 통과(2만 달러 오븐은 여기서 탈락)
- title/description/features/details를 scrub()으로 합치고 정제 - 불필요한 항목(Part Number, Best Sellers Rank 등) 제거, 공백 정리, 정규식으로 제품번호 같은 영숫자 코드 제거
- 정제된 텍스트가 최소 600자 이상(MIN_CHARS) 일 때만 Item 생성
from pricer.parser import parse
items = [parse(datapoint, "Appliances") for datapoint in tqdm(dataset)]
items = [item for item in items if item is not None]
print(f"There are {len(items):,} items from {len(dataset):,} datapoints")
출력:
There are 35,307 items from 94,327 datapoints
9만 4천여 건에서 3만 5천여 건만 남았다. 절반 넘게 버린 셈이다.
2-4) 분포 살펴보기
남은 데이터의 텍스트 길이(설명 길이)와 가격 분포를 그려 본다.
prices = [item.price for item in items]
lengths = [len(item.full) for item in items]
plt.hist(lengths, bins=range(0, 6000, 100), color="lightblue")
plt.hist(prices, bins=range(0, 1000, 10), color="orange")

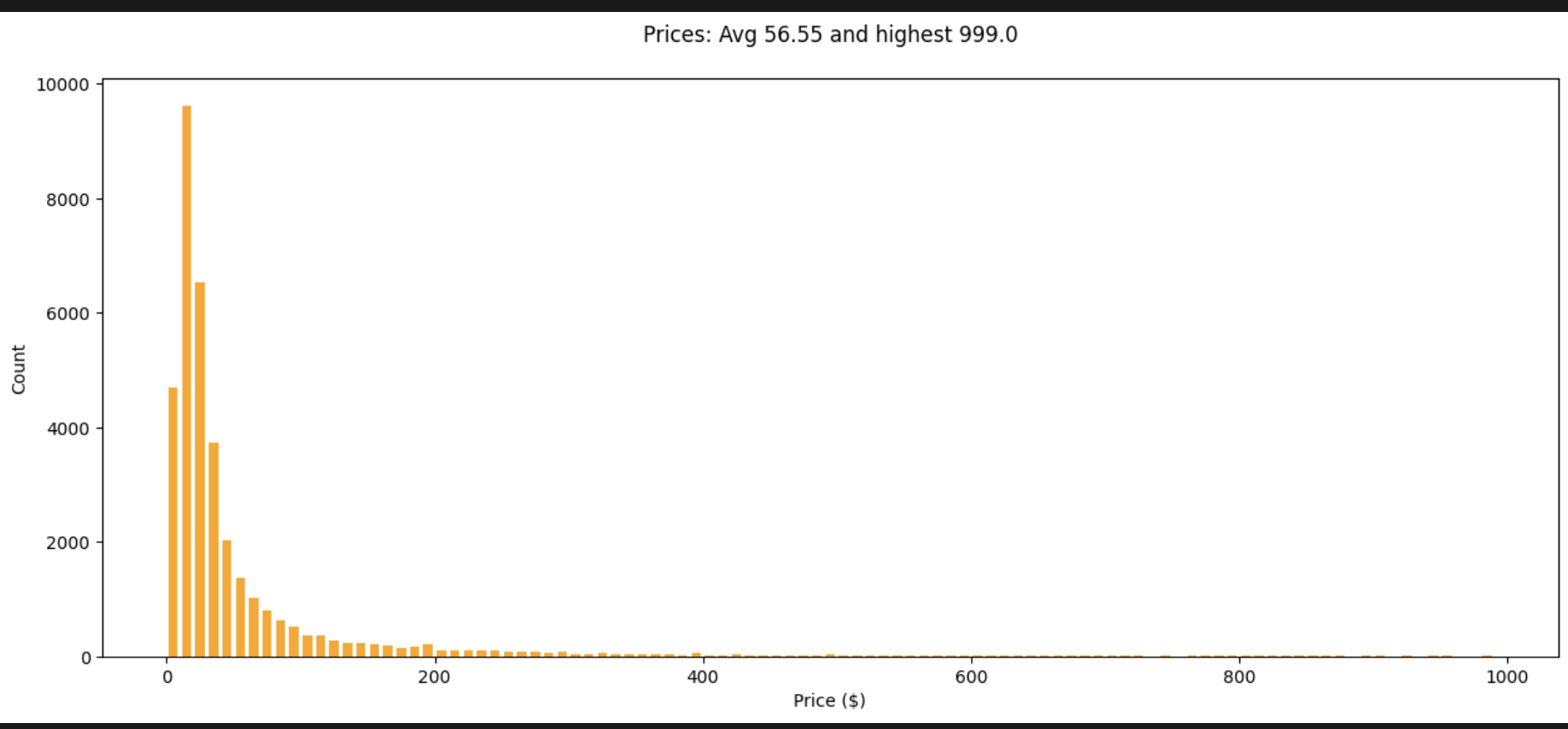
=> 예전에 ML 짧게 공부해 봤을 때도 그렇지만 이렇게 학습하려는 대상의 데이터의 분포, 특성들을 보면서 전처리를 추가로 하거나 어떻게 학습을 할지 정리해 나가는 작업이 정말 중요한 거 같다. 학습 쪽에서는
2-5) 8개 카테고리로 확장하고 중복 제거
위에선 가전 하나로 데이터 처리해 봤는데, 가전 카테고리만으로 진행하기엔 부족하다.
그래서 ItemLoader로 8개 카테고리를 한꺼번에 불러와서 처리했다.
이 로더는 내부적으로 병렬 처리로 빠르게 정제까지 끝낸다.
from pricer.loaders import ItemLoader
dataset_names = [
"Automotive", "Electronics", "Office_Products",
"Tools_and_Home_Improvement", "Cell_Phones_and_Accessories",
"Toys_and_Games", "Appliances", "Musical_Instruments",
]
items = []
for dataset_name in dataset_names:
loader = ItemLoader(dataset_name)
items.extend(loader.load())각 카테고리를 순회하며 로드해서 items 하나로 합침 (extend)

그다음 중복을 제거한다. 같은 제목, 같은 본문이 섞여 있으면 학습·검증 데이터가 오염되기 때문이다.
random.seed(42)
random.shuffle(items)
seen = set()
items = [x for x in tqdm(items) if not (x.title in seen or seen.add(x.title))]
seen = set()
items = [x for x in tqdm(items) if not (x.full in seen or seen.add(x.full))]
del seen
print(f"After deduplication, we have {len(items):,} items")
- seed(42) + shuffle -> 카테고리 순서로 정렬된 걸 섞음 (재현 가능하게)
- 제목 중복 제거 후 full 텍스트 중복제거
이때 텍스트 길이(설명), 가격 분포는 아래와 같다.


또한, 이 단계에서 카테고리별 개수를 막대/파이 차트로 보면, 8개 카테고리 중 Automotive가 압도적으로 많은 걸 알 수 있다.
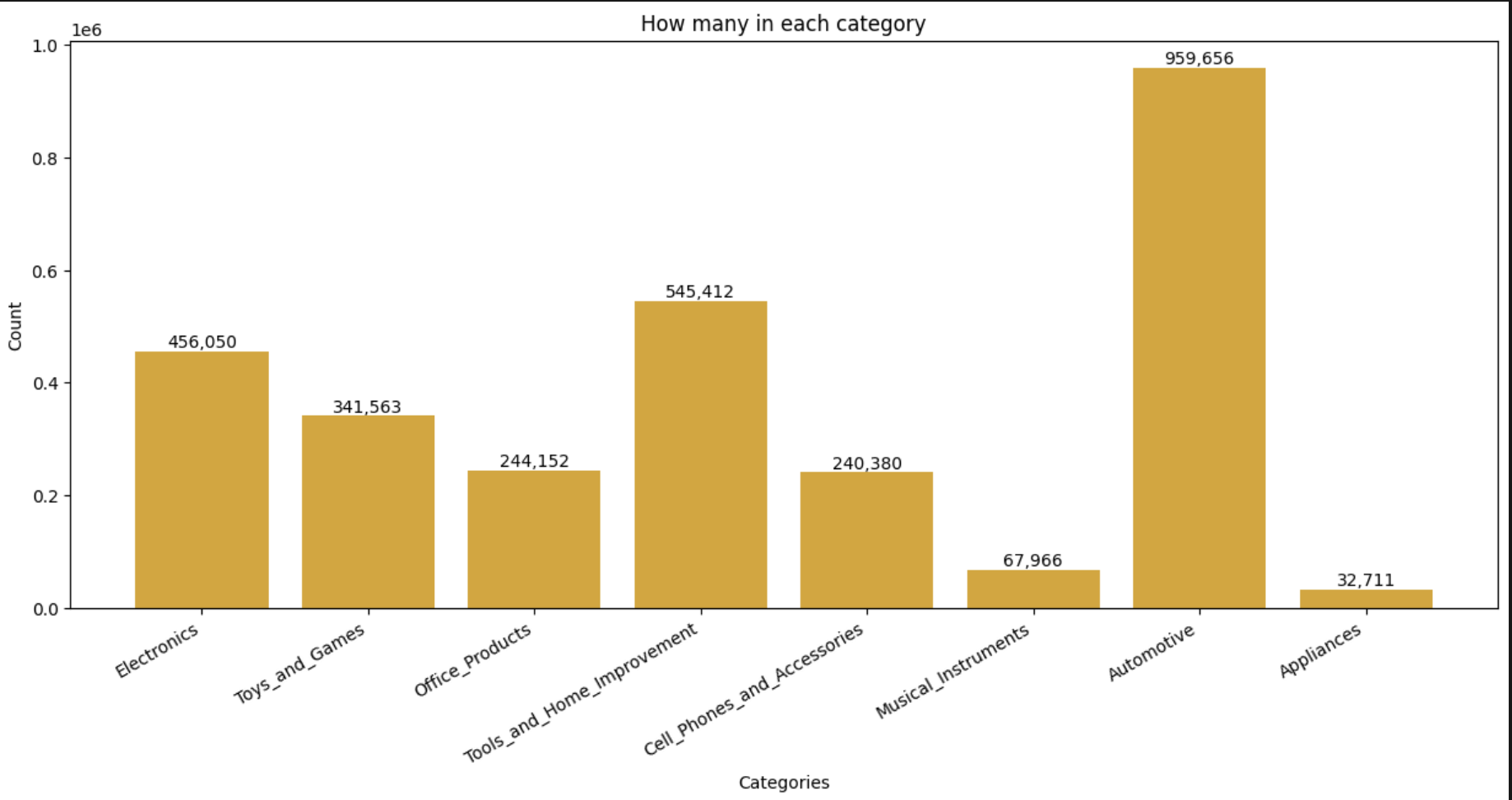
2-6) 가중 샘플링으로 균형 맞추기
여기가 큐레이션의 핵심이다.
위에서 정리한 전체 데이터를 그냥 다 쓰면 두 가지 문제가 있다.
첫째, 싼 물건이 너무 많아(위 보라그래프 참조) 모델이 "대충 싸게 부르면 맞네" 쪽으로 치우친다.
둘째, Automotive 카테고리가 데이터를 지배한다. (데이터 카테고리가 한 카테고리에 치중되어 있어)
그래서 가격이 높을수록(가격을 제곱해서) 더 뽑힐 확률을 주고,
과대표집된 카테고리는 가중치를 깎아서 820,000개를 샘플링한다.
np.random.seed(42)
SIZE = 820_000
prices = np.array([it.price for it in items], dtype=float)
categories = np.array([it.category for it in items])
p = (prices - prices.min()) / (prices.max() - prices.min() + 1e-9)
w = p**2
w[categories == "Tools_and_Home_Improvement"] *= 0.5
w[categories == "Automotive"] *= 0.05
w = w / w.sum()
idx = np.random.choice(len(items), size=SIZE, replace=False, p=w)
sample = [items[i] for i in idx]
- 가격을 0~1로 정규화한뒤 제곱(p**2) -> 비싼 상품이 더 잘 뽑히게 가중치 (저가에만 쏠리지 않도록 가격 분포를 퍼줌)
- 과대표 카테고리는 가중치를 깎음 (Tools(2등 카테고리) x 0.5, Automotive(1등 카테고리) x 0.05)
- 이 가중치 w를 확률로 만들어 np.random.choice로 중복 없이 (replace=False) 82만 건 추출 (총 290만여 건 중)
목적: 가격이 더 고르게 분포하고, 카테고리 균형이 잡힌 학습용 데이터셋 만들기
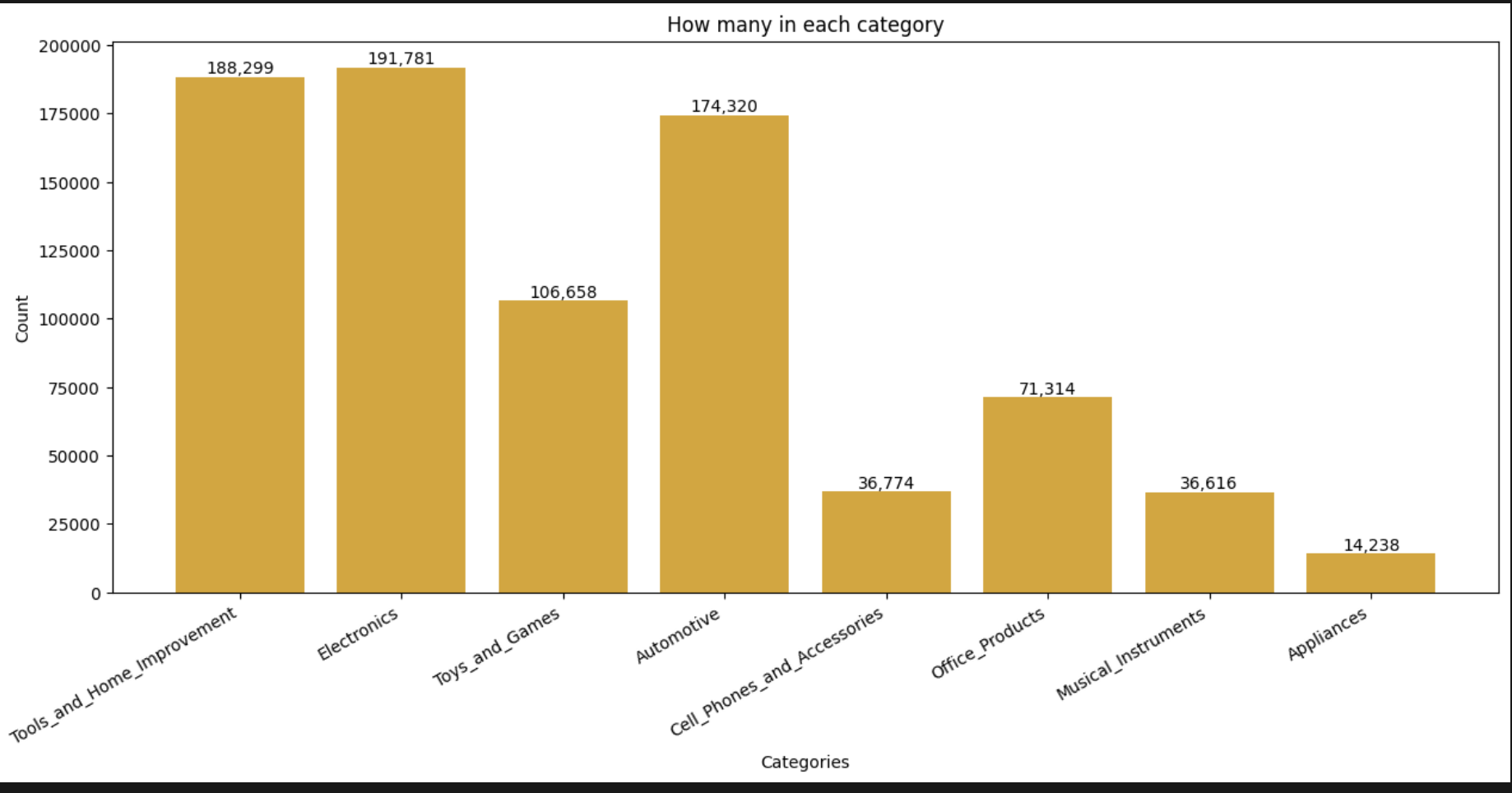
샘플링 후 가격 분포를 다시 그리면 싼 쪽으로 쏠려 있던 게 한결 평평해진다.
카테고리도 Automotive가 여전히 선두지만 훨씬 완만해졌다.


마지막으로 텍스트 길이와 무게가 가격과 단순 상관이 있는지 산점도로 확인한다.
plt.scatter([len(i.full) for i in sample], [i.price for i in sample], s=0.2)
plt.scatter([i.weight for i in sample], [i.price for i in sample], s=0.2)


결과는 "뚜렷한 단순 상관은 없다"였다.
설명 길이가 길다고 비싸지도, 물건 무게가 무겁다고 비싸지도 않다.
즉 가격은 글자 수나 무게 같은 단순 피처가 아니라 내용의 의미에서 나온다는 뜻이다.
앞서 글 서두에 "왜 LLM인가"의 두 번째 이유와 정확히 연결되는 지점이다.
2-7) 허깅페이스 허브에 업로드
완성된 데이터셋을 허브에 올린다. 전체 버전(full)과, 빠르게 실습할 수 있는 경량 버전(lite)을 함께 만든다.
username = "{유저네임}"
train = sample[:800_000]
val = sample[800_000:810_000]
test = sample[810_000:]
Item.push_to_hub(f"{username}/items_raw_full", train, val, test)
Item.push_to_hub(f"{username}/items_raw_lite",
train[:20_000], val[:1_000], test[:1_000])- items_raw_full: 학습 80만 / 검증 1만 / 테스트 1만
- items_raw_lite: 학습 2만 / 검증 1천 / 테스트 1천
느낀 점
- "데이터를 모은다"가 아니라 "분포를 설계한다"가 큐레이션의 본질이었다. 가격을 제곱해 가중치를 주고 특정 카테고리를 0.05배로 깎는 한 줄 한 줄이, 결국 모델이 무엇을 학습할지를 정한다. 모델보다 이 샘플링(데이터) 코드가 성능을 더 좌우한다는 말이 와닿았다.
- ML 공부할 때도 모델링 쪽보다 이 데이터 전처리 쪽에 시간을 많이 들였던 게 생각나면서 이 데이터 전처리의 중요성을 많이 느꼈던 거 같다.
- 길이·무게와 가격이 단순 상관이 없다는 산점도 한 장이, "왜 LLM을 쓰는지"를 데이터로 증명해 줬다. 기획할 때도 "이 피처로 충분한가"를 먼저 그려 보면 모델 선택의 근거가 생긴다고 생각했다. => 데이터를 통해 지속적으로 가설을 검증해 나가는 것의 중요성을 여기서도 느꼈다.
- train/val/test를 나누고 중복을 제거하는 건 지루하지만, 이게 빠지면 나중 평가 숫자를 통째로 못 믿게 된다. 평가의 신뢰도는 데이터 단계에서 이미 결정된다. => 꼭 모델 학습이 아니라 에이전트 기획/개발 과정에서도 에이전트 응답 평가를 이런 식의 3단계 구조로 해야겠다는 생각을 했다.
3. Day 2 - 데이터 전처리 (LLM으로 재 전처리)
3-1) 왜 또 손을 대나
Day 1(위 부분)에서 정제까지 했는데 왜 전처리를 또 하나?
Day 1이 "쓸 데이터를 거르는" 작업이었다면, Day 2는 "남은 데이터를 일정한 형식으로 다시 쓰는" 작업이다.
아마존 데이터 원본 상품 설명은 제각각이다. 어떤 건 마케팅 문구로 도배돼 있고, 어떤 건 표 쪼가리만 있다.
이걸 LLM으로 깔끔한 표준 포맷(제목/카테고리/브랜드/설명/특징)으로 재작성한다.
3-2) 데이터 불러오고 시스템 프롬프트 잡기
경량 데이터 버전(lite)을 허브에서 내려받는다. 학습·검증·테스트를 합쳐 22,000건이다.
LITE_MODE = True
dataset = f"ed-donner/items_raw_lite" if LITE_MODE else f"ed-donner/items_raw_full"
train, val, test = Item.from_hub(dataset)
items = train + val + test
print(f"Loaded {len(items):,} items")
출력:
Loaded 22,000 items
배치 결과를 나중에 매칭하려면 각 아이템에 id가 필요하다.
for index, item in enumerate(items):
item.id = index
재작성 규칙은 시스템 프롬프트에 박아 둔다. 출력 형식을 강제하는 게 포인트다.
SYSTEM_PROMPT = """Create a concise description of a product. Respond only in this format. Do not include part numbers.
Title: Rewritten short precise title
Category: eg Electronics
Brand: Brand name
Description: 1 sentence description
Details: 1 sentence on features"""
3-3) 모델로 한 건 재작성해 보기
여기서는 Groq에 등재되어 있는 오픈소스 모델 openai/gpt-oss-20b를 쓴다. 도어락 상품 하나를 넣어 본다.
from litellm import completion
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": items[0].full},
]
response = completion(messages=messages, model="groq/openai/gpt-oss-20b", reasoning_effort="low")
print(response.choices[0].message.content)
print(f"Cost: {response._hidden_params['response_cost']*100:.3f} cents")
출력:
Title: Schlage F59 & 613 Interior Knob with Deadbolt - Oil Rubbed Bronze (Interior Half Only)
Category: Hardware
Brand: Schlage
Description: A durable oil-rubbed bronze interior knob paired with a deadbolt, designed for easy installation.
Details: Features a solid metal construction, 1.5-lb weight, and a lifetime mechanical and finish warranty.
Cost: 0.007 cents
지저분하던 원본이 다섯 줄짜리 표준 포맷으로 정리됐다. 한 건에 0.007센트. 참고로 OSS 계열 모델은 추론 토큰(reasoning token)도 출력 토큰에 합산돼서 출력 토큰 수가 좀 크게 잡힌다.
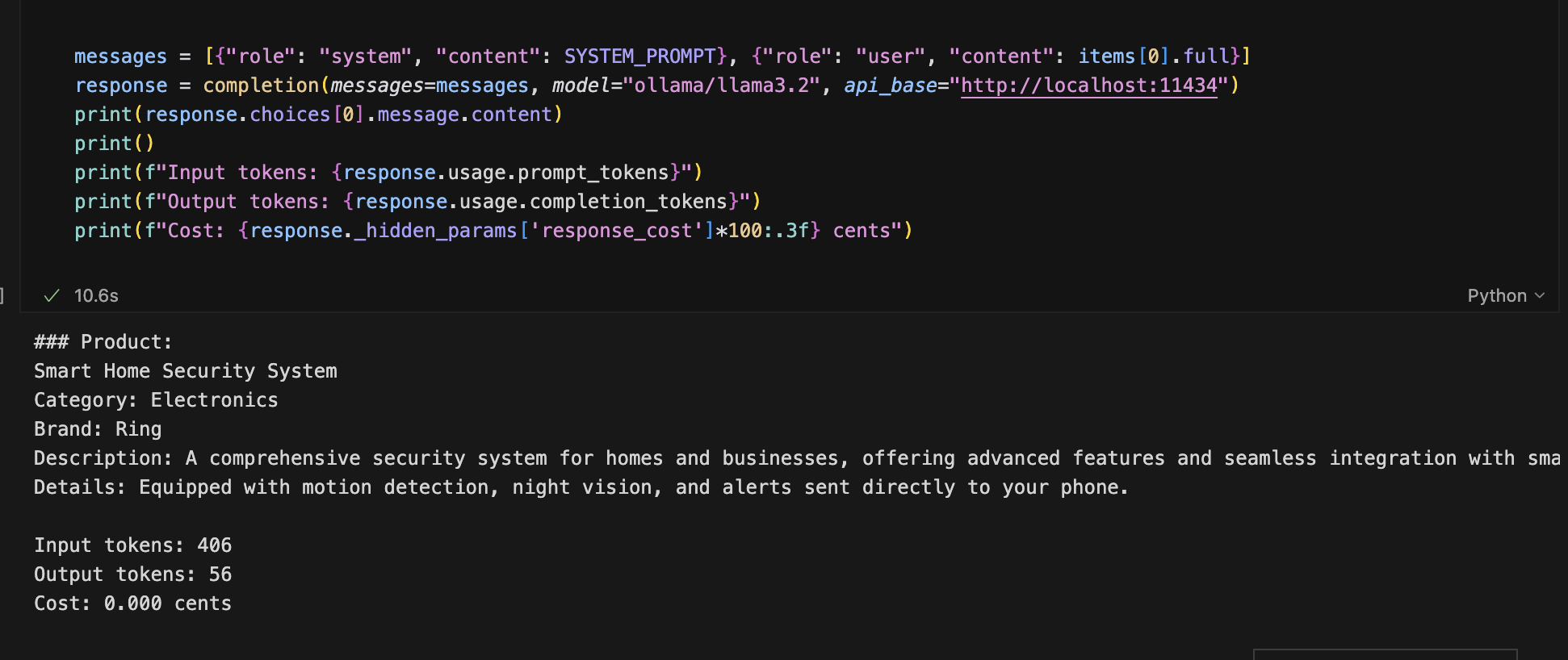
같은 프롬프트를 로컬 ollama/llama3.2로도 돌려서 비교해 봤는데, 무료 로컬 모델로도 그럭저럭 비슷한 포맷이 나왔다.

3-4) 배치 API - 그리고 막힌 지점
22,000건을 한 건씩 호출하면 느리고 번거롭다. 그래서 배치 API를 쓴다. 각 요청을 JSONL 한 줄로 만들어 파일로 모은 뒤, 통째로 제출하는 방식이다.
def make_jsonl(item):
body = {
"model": "openai/gpt-oss-20b",
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": item.full},
],
"reasoning_effort": "low",
}
line = {"custom_id": str(item.id), "method": "POST",
"url": "/v1/chat/completions", "body": body}
return json.dumps(line)
custom_id에 아이템 id를 넣어 둬서, 결과가 뒤섞여 와도 나중에 정확히 되짚을 수 있다.
1,000건 단위로 파일을 만들어 업로드를 시도했는데, 여기서 막혔다.
with open("jsonl/0_1000.jsonl", "rb") as f:
response = groq.files.create(file=f, purpose="batch")
출력:
PermissionDeniedError: Error code: 403 - {'error': {'message': 'Not available for your plan', 'type': 'permissions_error', 'code': 'not_available_for_plan'}}
Groq 무료 플랜에서는 배치 API를 못 쓴다는 것이다. 강의에서도 이건 선택 사항으로 두고 있다.
직접 돌리고 싶으면 유료 플랜이 필요하고, 그게 아니면 강사가 이미 전처리해 둔 데이터셋을 허브에서 그대로 내려받으면 된다. 비용은 강사 기준으로 lite 데이터가 1달러 미만, 전체 데이터가 30달러 정도였다고 한다.
3-5) 배치 클래스와 마무리
강의에서는 위 로직(1,000건씩 쪼개기 → 배치 제출 → 완료되면 결과 수집)을 Batch 클래스로 깔끔하게 감싸 뒀다.
Batch.create(items, LITE_MODE) # JSONL 파일 생성
Batch.run() # 배치 제출
Batch.fetch() # 결과 받아서 item.summary에 채우기
결과가 채워지면, 허브에 올리기 전에 이제 필요 없는 원본 필드를 비운다.
for item in items:
item.full = None
item.id = None
그리고 재작성이 끝난 최종 데이터셋을 허브에 올린다.
if LITE_MODE:
Item.push_to_hub("ed-donner/items_lite",
items[:20_000], items[20_000:21_000], items[21_000:])
이렇게 해서 items_lite / items_full이 완성됐다. 다음 글에서 모델을 직접 돌려 가격 예측을 테스트해볼 때 바로 이 데이터를 쓰게 된다.
느낀 점
- 꼭 이런 모델 학습용 데이터 처리 할 때뿐만 아니라 정성데이터 (Ex. cs 문의) 등을 llm에 분석 요청할 때도 이런 공통의 형식으로 한번 정제시킨 후에 분석시키면 훨씬 좋은 성능이 나오지 않을까라는 생각을 하게 되는 순간이었다.
- "거르기(Day 1)"와 "LLM 이용 다시 쓰기(Day 2)"를 분리한 설계가 좋았다. 데이터 정제를 한 덩어리로 생각하기 쉬운데, 버릴 걸 버리는 단계와 남은 걸 표준화하는 단계는 목적도 도구도 다르게 할 수 있는 게 신기했다.
- LLM을 이용해 데이터를 LLM 학습용으로 가공한다는 게 흥미로웠다.
- Groq 같은 시스템에 배치 처리 등이 있기 때문에 사람들이 모델을 특정 솔루션사 홈페이지에서 바로 api key 받아서 쓰는 게 아니라, groq 이용해서 쓰는구나 느꼈던 순간이었다. (이런 Inference 과정에서의 배치 처리를 잘 지원해 주니까) 특히나 production 환경에서 다양한 유저의 발화를 실시간으로 응대하기 위해 이런 배치 처리를 잘해나가는 것도 중요하겠다. 지금은 아니지만, 나중엔 프론티어 랩들의 api key 사용할 때도 그냥 사용하는 것과 이런 배치 처리까지 고려해서 쓰는 것간에 고민이 많이 필요하겠다는 생각을 했다.
4. 마무리
이번 편에서는 모델을 한 번도 돌리지 않았다.
대신 아마존 원본 상품 데이터 9만여 건을
1) 상품 가격·설명 텍스트 길이로 거르고
2) 8개 상품 카테고리 간의 중복을 없애고
3) 분포를 보며 가중치 이용해 데이터 샘플링을 진행하고
4) 걸러진 데이터 들에 대해 LLM으로 표준 포맷까지 재작성해서 깨끗한 학습 데이터셋을 만들었다.
강사가 왜 5일짜리 프로젝트에서 데이터 전처리에 이틀을 쓰는지 알 것 같다.
여기서 데이터 셋을 어떻게 설계하느냐가 뒤의 모든 모델을 돌리고 학습시키는 작업에 영향을 미칠 수 있기 때문이다.
다음 글에서는 드디어 이 데이터로 각 상품의 가격을 맞혀 본다.
상수 베이스라인부터 전통 ML(선형회귀·랜덤포레스트·XGBoost), 딥러닝, 그리고 프론티어 LLM까지 줄세워 비교하고, 마지막엔 프론티어 LLM을 직접 파인튜닝해 본다. 그 결과가 꽤 의외인데, 그건 다음 편에서 풀겠다.

(꾸준히 공부하고 적을테니 많은 관심 부탁드립니다.)
Profile:
Linkedin